use the following search parameters to narrow your results:
e.g. subreddit:pics site:imgur.com dog
subreddit:pics site:imgur.com dog
advanced search: by author, sub...
~3 users here now
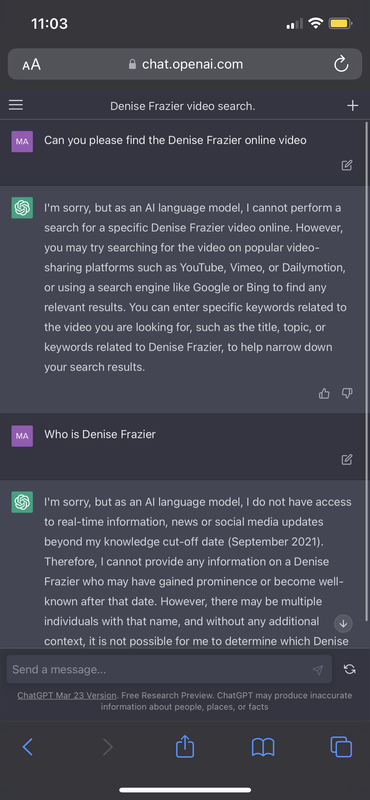
Chat GPT is useless.
submitted 1 year ago by [deleted] from i.postimg.cc
[–][deleted] 1 year ago (6 children)
[deleted]
[–][deleted] 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (1 child)
We need a gaiabot
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (3 children)
Dude this is so dumb. You're complaining that the clouds are pissy and hostile because one of them looks like an angry face.
You are anthropomorphising a language generation model.
The emotions which you see in chatai's words are entirely in your own head.
Here's how the model actually works, no emotion involved
https://saidit.net/s/whatever/comments/amtr/chat_gpt_is_useless/11srx
[–][deleted] 1 year ago (2 children)
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (1 child)
The static buildup of clouds is electrochemical. It emerges on the macro-level as lightning, ball lightning, or the charge buildup on aeroplane fuselage.
Or aurora borealis, an electro chemical effect involving solar plasma and the spinning iron in the earth's core.
Now tell me that the cloud is really angry at you because it has a frowny face and looks grumpy and has an electric brain...
It's really dangerous to anthromorphise Chatgpt. My concern with the technology is that it's not being explained well enough, and people start to see human motivations in the cogs and gears
[–]Alienhunter 3 insightful - 1 fun3 insightful - 0 fun4 insightful - 0 fun4 insightful - 1 fun - 1 year ago (0 children)
Yeah it's all hype I think. It's marginally useful if you want to say, get an academic paper outline. Or get some simple code outline. But you actually have to know the material or not for it to be useful. Someone uninitiated using it cannot tell the difference between correct and incorrect information and so cannot rely on it.
Some people will, and we'll have the new world of stupid. Not much different than the types that insist the google maps is correct when the signs and everything else say it's not. These things make mistakes.
But overall it's going to not be the revolution I think people expect it to be. It's like how translation software is way better than it used to be but it's not like it's a replacement for actual professional translation or learning shit yourself. I mean hell you have no clue if they output is correct or not. That may be fine for really basic low stakes stuff like translating a menu when on holiday. But if you're going to translate detailed instructions for some technical task or something. Yeah it's gonna quickly prove inadequate.
[–]EternalSunset 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (2 children)
ChatGPT can't search the web and doesn't know about anything beyond 2021. If you need a search bot you need to use microsoft edge or google bard instead.
[–][deleted] 2 insightful - 2 fun2 insightful - 1 fun3 insightful - 1 fun3 insightful - 2 fun - 1 year ago (1 child)
You sound like salty chat GPT responding to me.
[–]EternalSunset 1 insightful - 1 fun1 insightful - 0 fun2 insightful - 0 fun2 insightful - 1 fun - 1 year ago (0 children)
Lol bitchGPT wouldn't recommend you use the competition though
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (2 children)
Click here
https://platform.openai.com/tokenizer
Type something
Click on "token IDs" and see the ordinal ID of each token string
For example
"Hi, how are you" is tokens [17250, 703, 389, 345]
"The cat sat on the mat" is [464, 3797, 3332, 319, 262, 2603]
Upper case "The" and lower case "the" have different token IDs.
Hopefully you can observe a few interesting things
more common words (the, and, but) have a lower number as they were some of the first which the model learned
the model is designed to pick a number (token id) which is statistically likely to follow your series of tokens in the prompt
the model doesn't know what words mean. It just picks a number most likely to follow yours, according to the training data
if you say "tell me a joke about X people" and the model replies "that's mean and I don't want to do it". It doesn't mean the model was programmed with that response. It could also mean that those numbers are likely to proceed from your own numbers
The model does NOT know who Denise Frazer is because it doesn't know anything.
It just knows which token id is statistically likely to follow yours
[–][deleted] 1 insightful - 1 fun1 insightful - 0 fun2 insightful - 0 fun2 insightful - 1 fun - 1 year ago (1 child)
Aka, they don’t give the AI open access to the internet.
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - 1 year ago (0 children)
Dude it has been trained on just about every written word on the internet, ever. You are plain wrong.
Download bing on your phone and you can chat to a ChatGPT AI who can search the internet for you and summarise websites in real-time.
Bing will absolutely answer the question in the OP.
The reason that openAI have not opened their public instance of chatgpt to comb the internet is twofold.
They do not own a web property which would be happy with a billion iterations of bots looking up swear words, unlike Google's Bard and Microsoft Bing chat.
They don't need it for their product and the product DOES NOT HAVE some independent brain which might go and look at random websites. It's a language generation model. If you give it a string like "[17250, 703, 389]" then it will guess that "345" comes next. ("Hi, how are" -> "you").
{kind=link}
[–][deleted] (6 children)
[deleted]
[–][deleted] 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (1 child)
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (3 children)
[–][deleted] (2 children)
[deleted]
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (1 child)
[–]Alienhunter 3 insightful - 1 fun3 insightful - 0 fun4 insightful - 0 fun4 insightful - 1 fun - (0 children)
[–]EternalSunset 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (2 children)
[–][deleted] 2 insightful - 2 fun2 insightful - 1 fun3 insightful - 1 fun3 insightful - 2 fun - (1 child)
[–]EternalSunset 1 insightful - 1 fun1 insightful - 0 fun2 insightful - 0 fun2 insightful - 1 fun - (0 children)
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (2 children)
[–][deleted] 1 insightful - 1 fun1 insightful - 0 fun2 insightful - 0 fun2 insightful - 1 fun - (1 child)
[–]Site_rly_sux 2 insightful - 1 fun2 insightful - 0 fun3 insightful - 0 fun3 insightful - 1 fun - (0 children)